
DS 1
Frequent Item Sets
Definition
Given a support threshold s, sets of items that appear in at least s baskets.
Association Rules
: if a basket contains all of , it is likely to containConfidence
Interest
Difference between its confidence and the fraction of baskets containing j
- Positive: high conf low Pr, j is rare but frequently co-occurs with I (complementary)
- Negative: low conf high Pr, j is frequent but seldom co-occurs with I (substitutive)
Find Association Rules
- Find all frequent itemsets I
- For every subset A of I, generate a rule
- Output rules above confidence threshold
Compact the Output
- Maximal frequent itemsets: No superset is frequent
- Closed itemsets: No superset has same count
Find Frequent Itemsets
Critical resource: Main Memory
Counting Pairs in Memory
Approach 1
- Count all pairs using a matrix
- 4 bytes per pair
- pair{i, j} is at
Approach 2
- Table of Triples[i, j, count(i, j)]
- 12 bytes per pair (but only for pairs with count > 0)
- Beats approach 1 if less than possible pairs actually occur
A-Priori Algorithm
Computation Model
- Association-rule algo reads the data in passes (all baskets read in turn)
- True cost usually the number of disk I/Os
A-Priori (A two-pass approach)
Key idea: monotonicity
- If a set of items I appears at least s times, so does every subset J of I
Contrapositive for pairs
- If item i doesn’t appear in s baskets, then no pair including i can appear in s baskets
Pass 1
Read baskets and count in main memory the occurrences of each individual item
- Require only memory proportional
Pass 2
Read baskets again and count in main memory only those pairs where both elements are frequent (from Pass 1)
- Require memory proportional to O(frequent-item^2)
- Plus a list of the frequent items
Frequent Triples+
For each k, construct two sets of k-tuples:
PCY (Park-Chen-Yu) Algorithm
- Most memory is idle in pass 1 of A-Priori, only store individual item counts
Pass 1
Maintain a hash table with as many buckets as fit in memory
- Each bucket counts, not the actual pairs

Pass 2
Only count pairs that hash to frequent buckets
- Replace the buckets by a bit-vector to reserve memory for pass-2
- 4-byte integer counts are replaced by bits
- Bit-vector requires memory (1 byte = 8 bits)
- Decide which items are frequent and list them for pass 2

Count all pairs {i, j} that are candidate pairs:
- Both i and j are frequent items
- Pair {i, j} hashes to a bucket whose bit in the bit vector is 1 (i.e., a frequent bucket)
- These are necessary conditions for the pair to be frequent
Multistage Algorithm
Pass 1 of PCY, rehash only those pairs that qualify for pass 2 of PCY
- i and j are frequent
- {i, j} hashes to a frequent bucket from pass 1
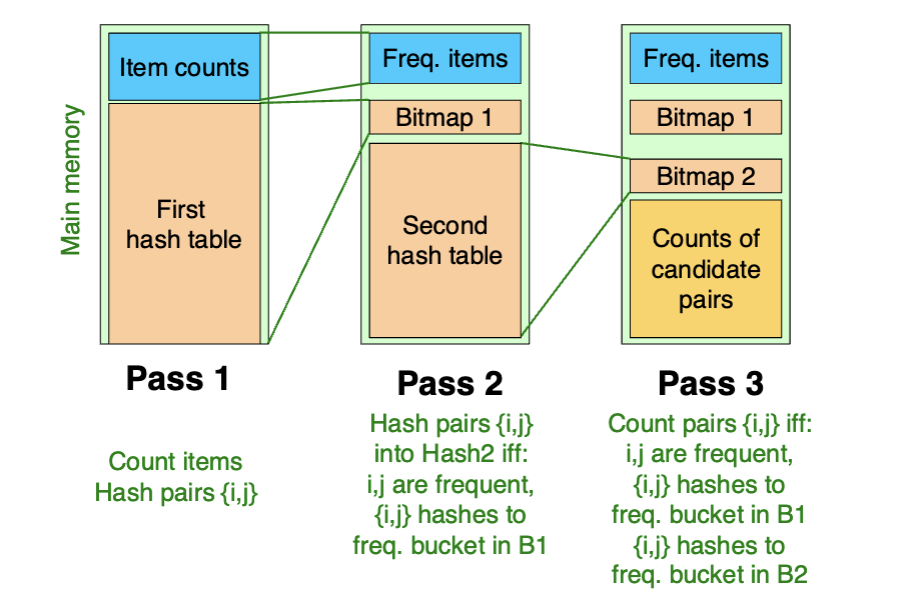
Pass 3
Count {i, j} that:
- i and j are frequent items
- Using the first hash function, the pair hashes to a bucket whose bit in the first bit-vector is 1
- Using the second hash function, the pair hashes to a bucket whose bit in the second bit-vector is 1
Hints
- Two hash functions have to be independent
- Check both hashes on pass 3
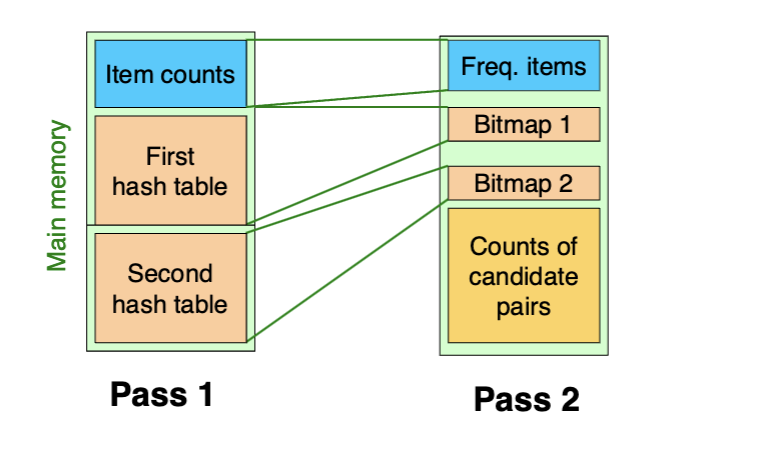
Multihash
Use several independent hash tables for pass 1
- Risk: The average count doubles because half bucket numbers
- Ensure most buckets won’t reach count s
Less Pass
1. Random Sampling
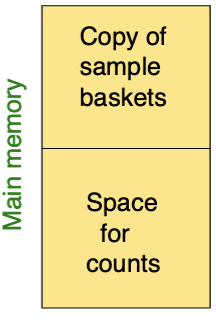
- No need to pay for disk I/O
- Reduce Support threshold proportionally to match the sample size
2. SON Algorithm
Repeatedly read small subsets of the baskets into main memory